My role: As the only UX designer in the Machine Learning Solutions Lab, I was in charge of the end-to-end UX process. I conducted UX research to identify/validate needs and define requirements. I generated initial design concepts and conducted feedback sessions to gather input and collect data to drive design iterations. I created prototypes and high-fidelity UIs, as well as the necessary assets required for implementation. All of this using a collaborative approach, working closely with the engineering team to rapidly identify optimal solutions that were also feasible within the given time-frame. Also collaborated closely with PMs and business stakeholders to ensure the solutions meet business needs.
The Medical Transcription Analysis demo integrates Amazon Transcribe Medical, Amazon Comprehend Medical and Amazon Translate to transcribe audio data, extract key medical components, tag the data to their corresponding entities and translate the output to a different language. Automating the medical transcription and comprehension process makes it easier for healthcare professionals to focus on patient care. This integration also processes the results into easily digestible formats, which reduces the manual effort needed to record and digitize information.
To access the MTA source code, see Medical Transcription Analysis on GitHub .This solution has been made open source so that AWS customers can extend and incorporate the solution into their workflows. Possible extensions include integrating into EHR systems, adding a persistent storage layer, building analytics over collected data, enabling batch processing and enhancing the user experience for multi-speaker / conversational use cases.
Deploying MTA
The deployment creates an Amazon Simple Storage Service (Amazon S3) and Amazon CloudFront backed website with authentication provided by Amazon Cognito. It also creates an AWS Identity and Access Management (IAM) role with permissions to Amazon Comprehend Medical and Amazon Transcribe Medical, and an API to retrieve temporary credentials from the role. The deployment also includes Amazon DynamoDB tables, an Amazon S3 bucket for data storage and Amazon Athena for data analytics.
Using MTA
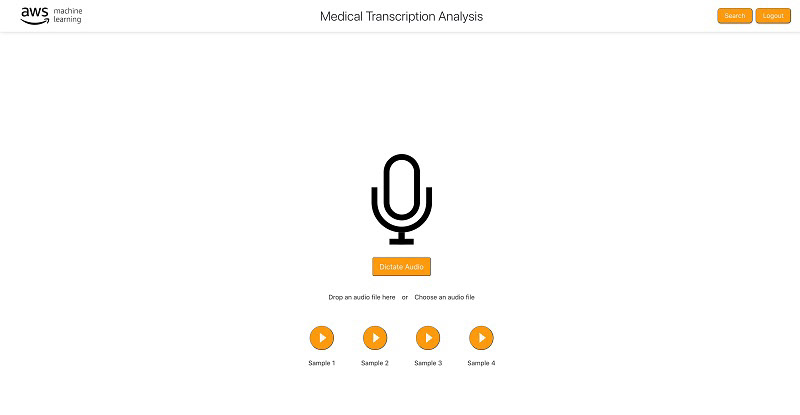
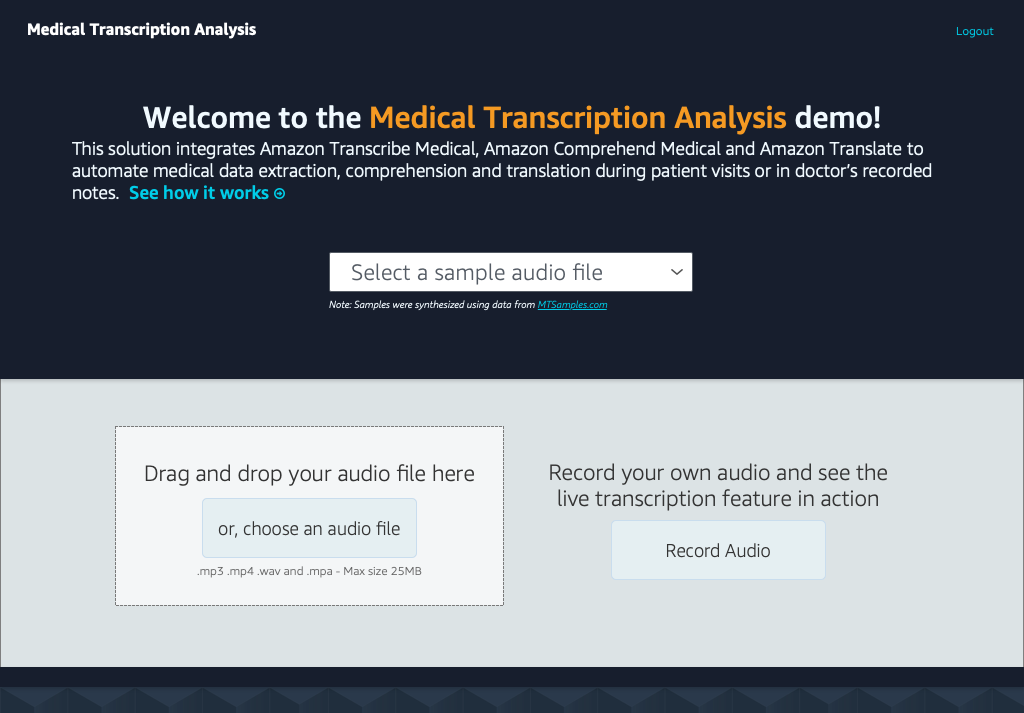
After deploying the application, you'll receive an email with login credentials. When you log in, you are directed to the homepage. The homepage offers options to dictate audio using the microphone, upload a sample audio file or play a sample audio files.
The screenshot below shows what the transcription looks like. You can speak directly to the microphone or we’ve pre-loaded audio files of clinical encounters that users can try to test the feature.
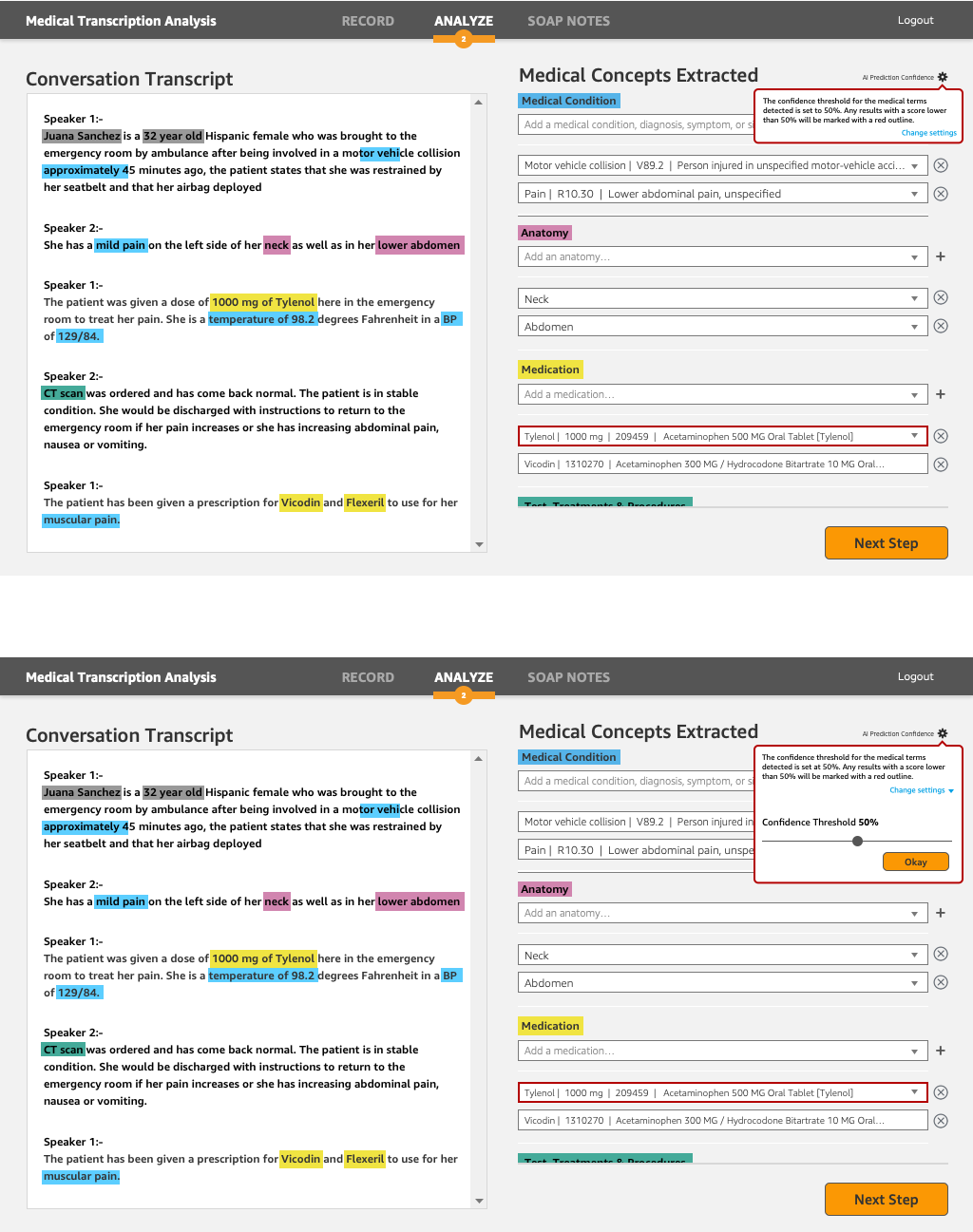
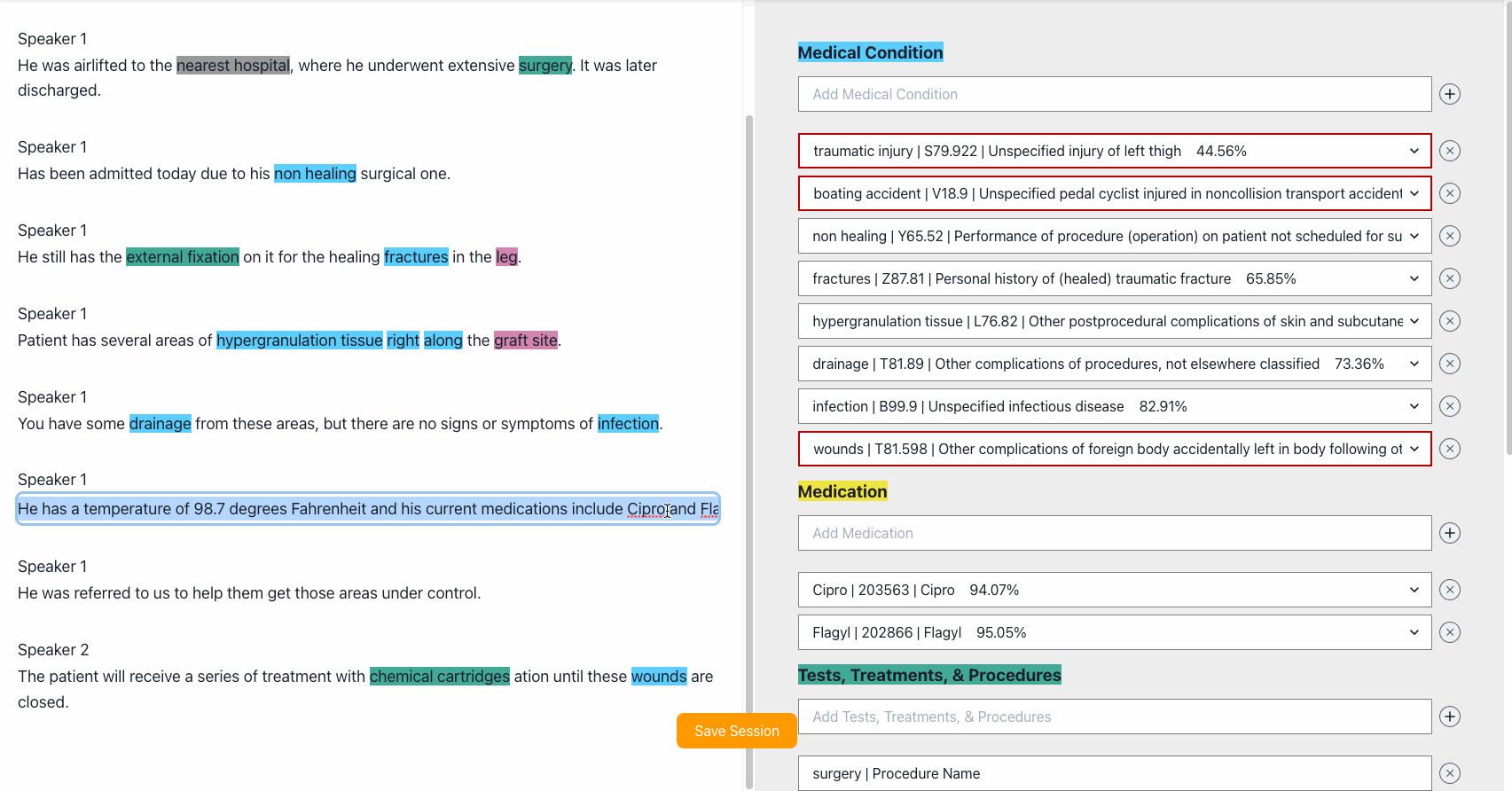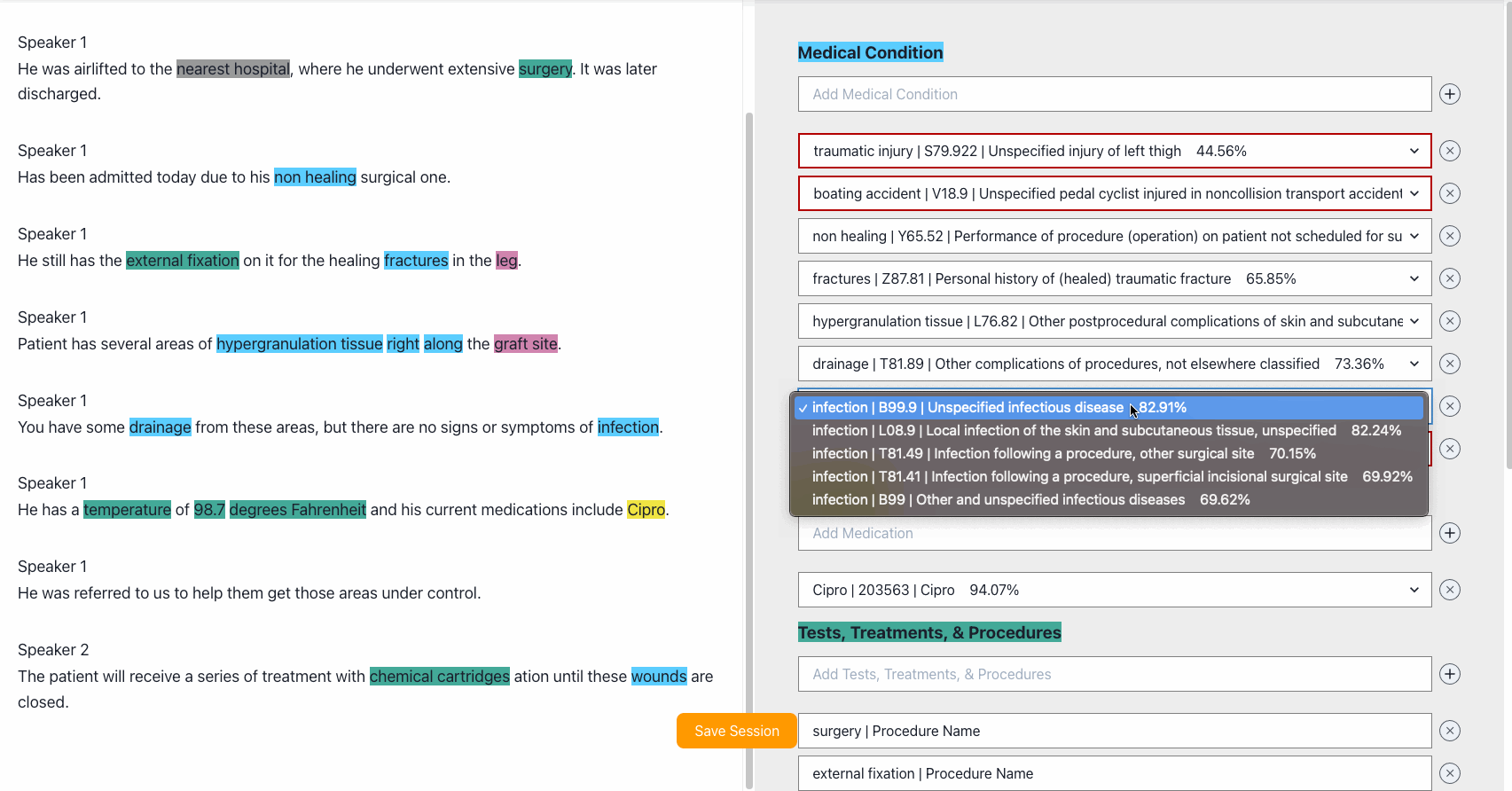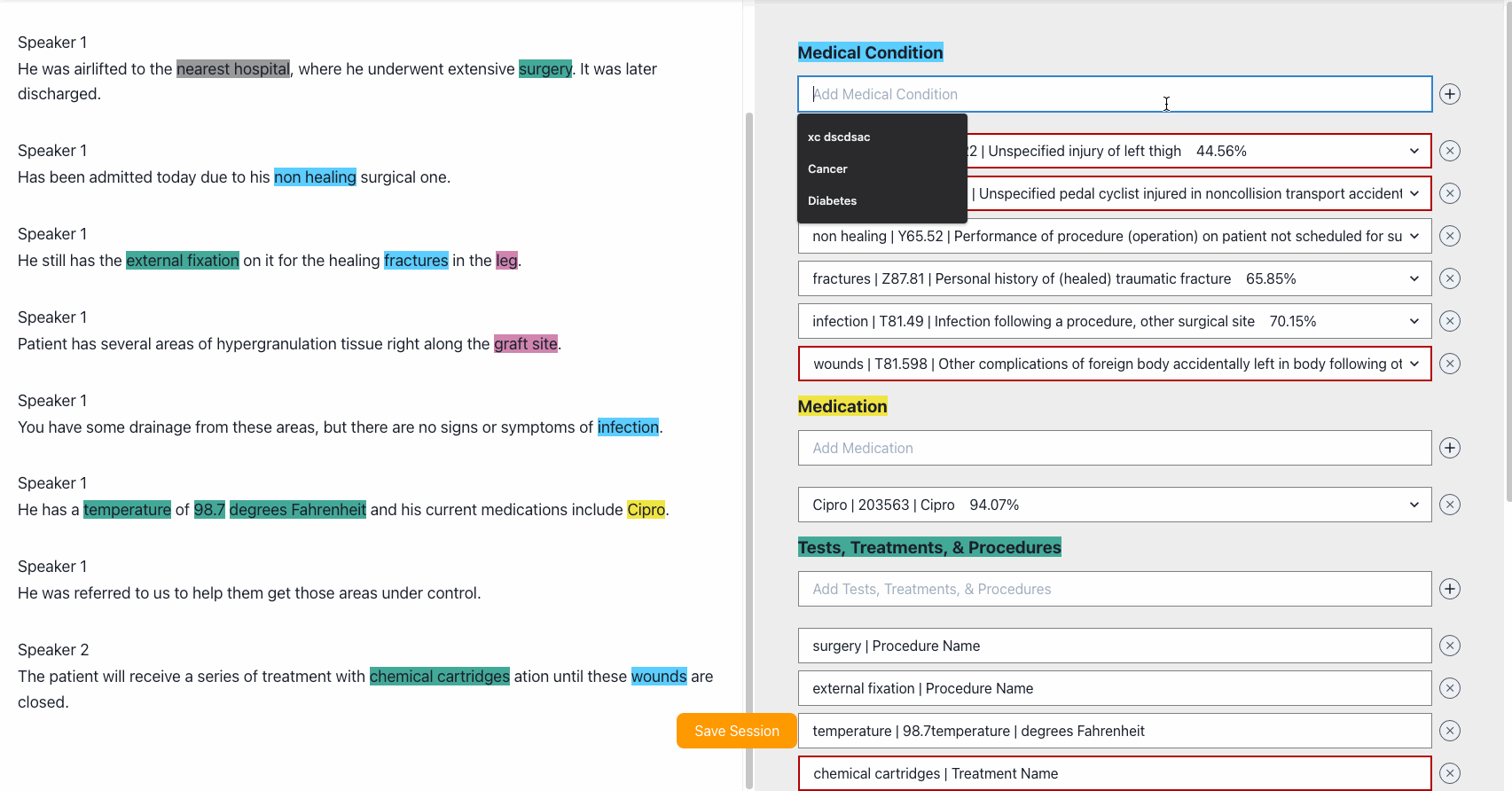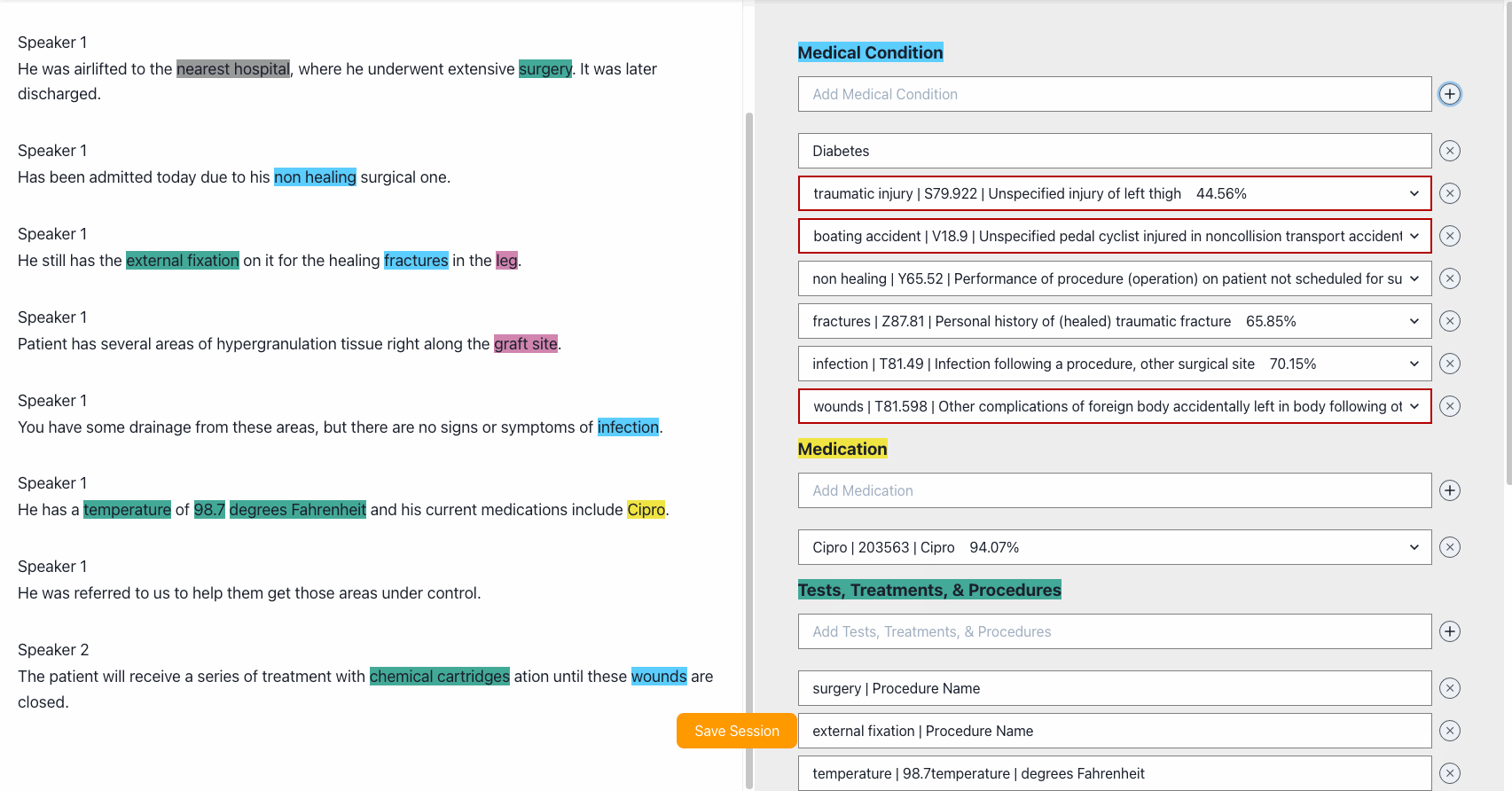
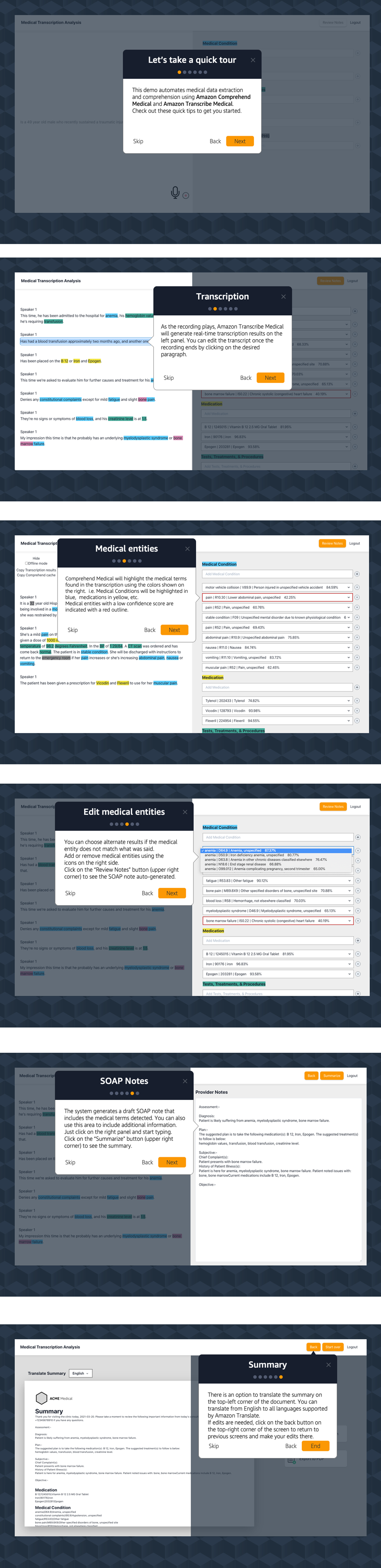
Once you choose a sample audio or speak directly using the microphone button, MTA will open a WebSocket with Amazon Transcribe Medical and will render real-time transcription results on the UI. You can highlight words that fall into different medical categories. The following screenshot shows a transcription from the sample audio.
Once the transcription is done, you can make edits to the transcription. Fix errors that the transcription may have, or you can redact PHI.
Editing the transcription will also update the entities.
Edit entities. Comprehend Medical gives us a few options for what the entities might be. ICD10 codes and confidence scores.
Edit entities. Comprehend Medical gives us a few options for what the entities might be. ICD10 codes and confidence scores.
We provide a few options based on confidence scores. Use dropdown to select the entity or ICD-10 instance that matches better the transcription.
Notes
Once you are happy with the transcription and the entities detected, we pre-populate clinical notes with pre-determined fields (assessment, diagnosis, subjective, objective) that match the requirements for healthcare providers after a clinical event. The UI uses a regular text-input field to enable users to edit this information as needed.
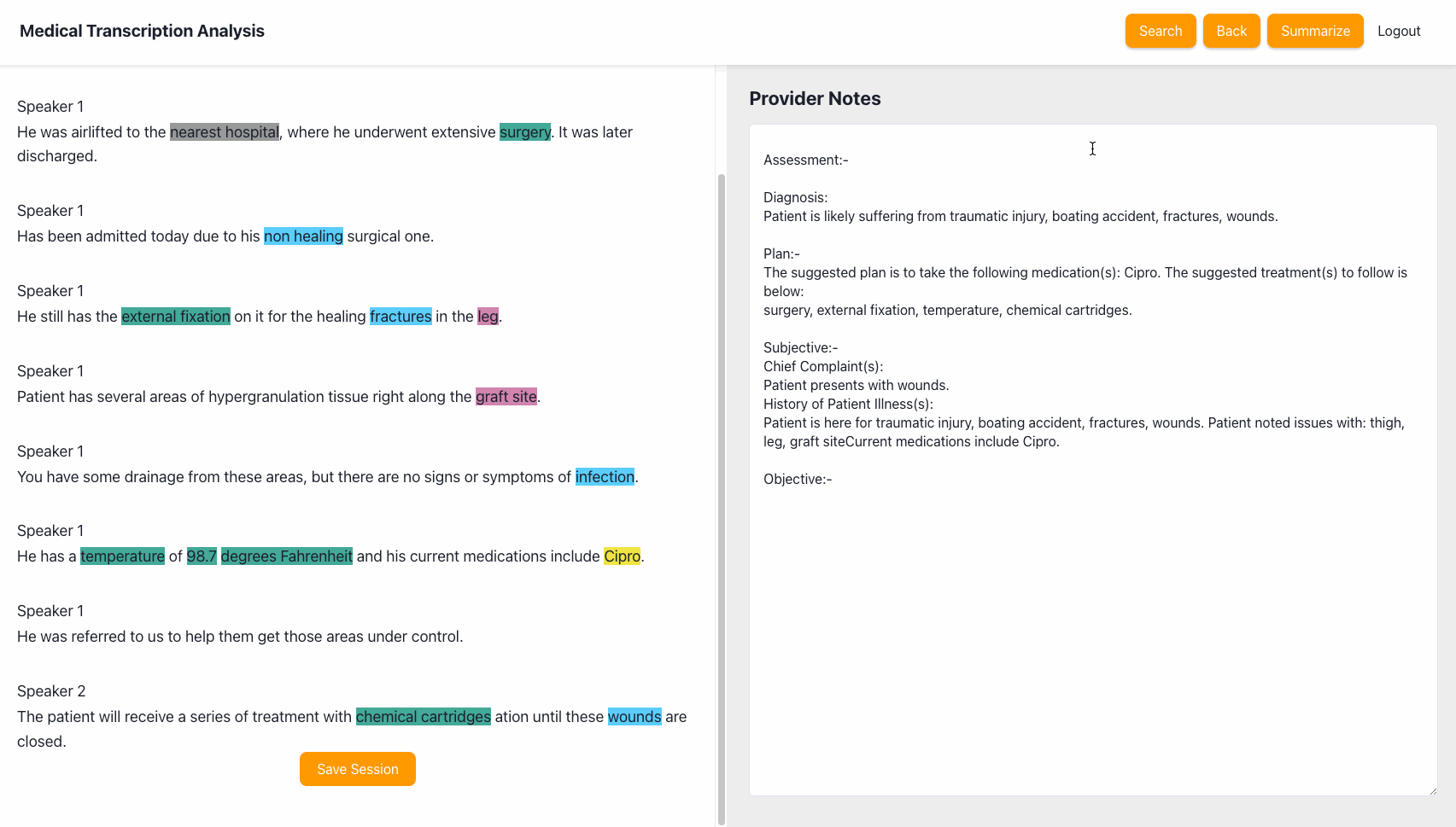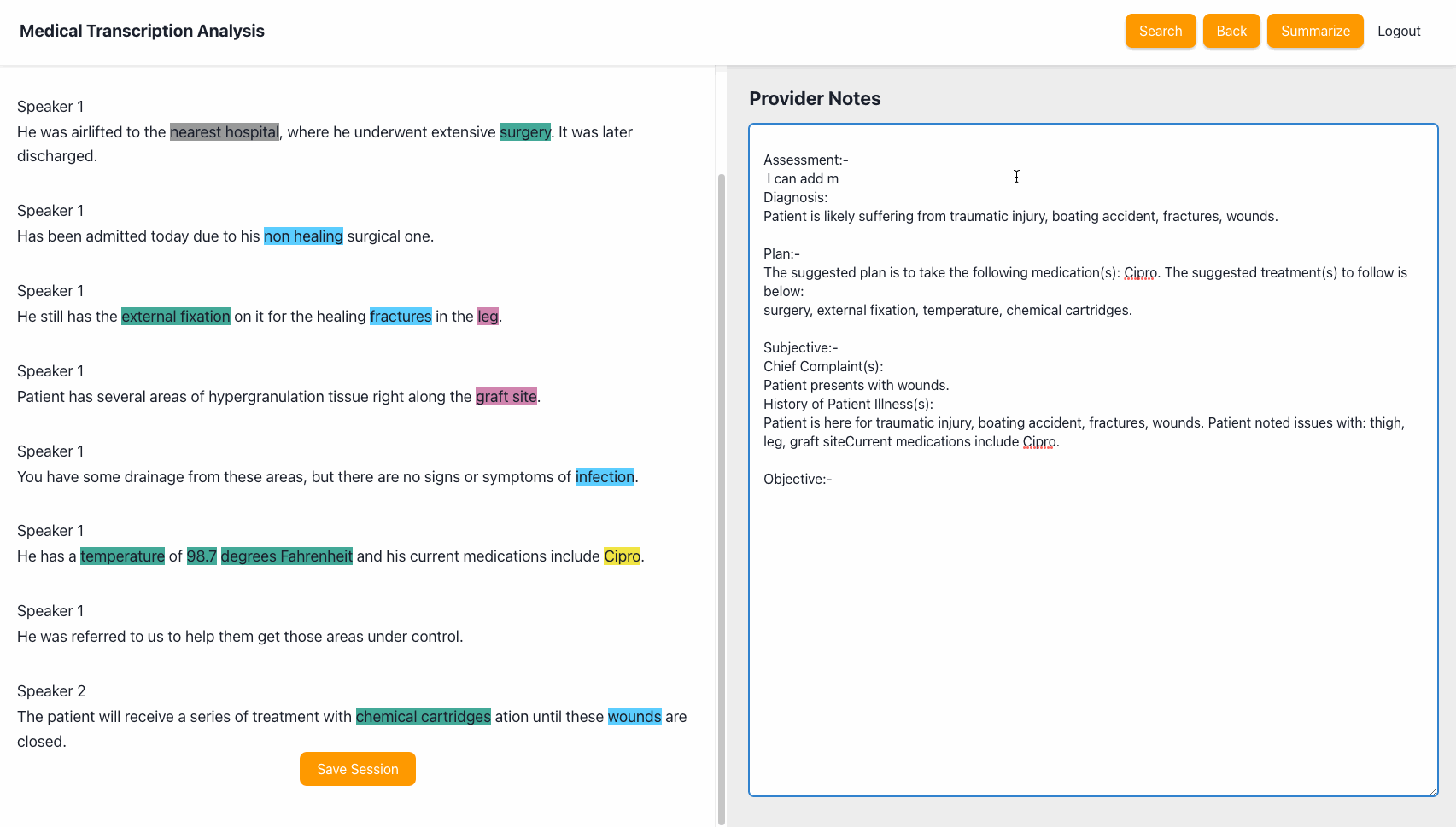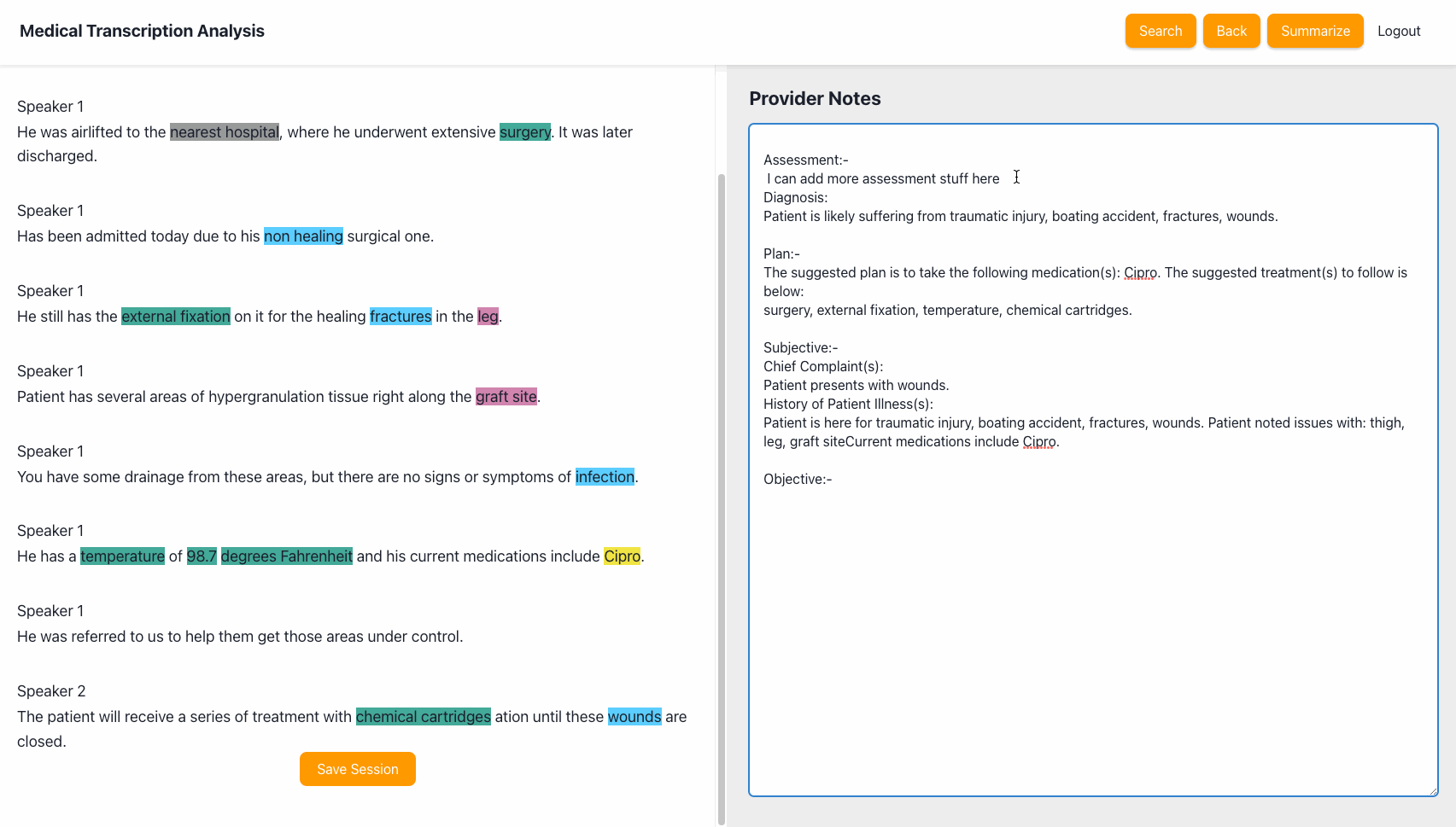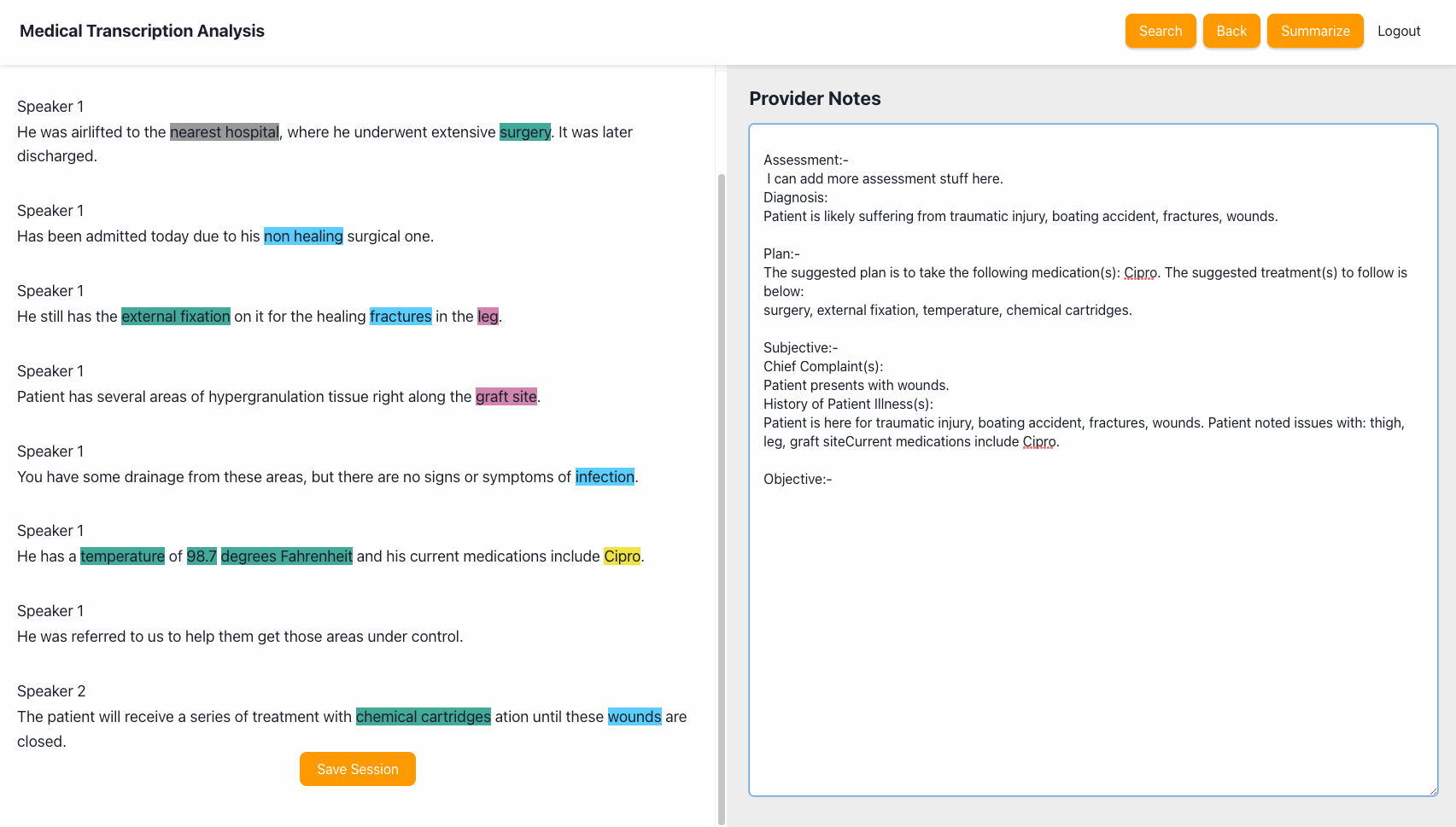
Summary
Once the notes are complete, the application will generate a summary that includes the detected entities, the consultation transcript and the notes. It also provides an option to translate the summary to any of the 71 languages supported by Amazon Translate.
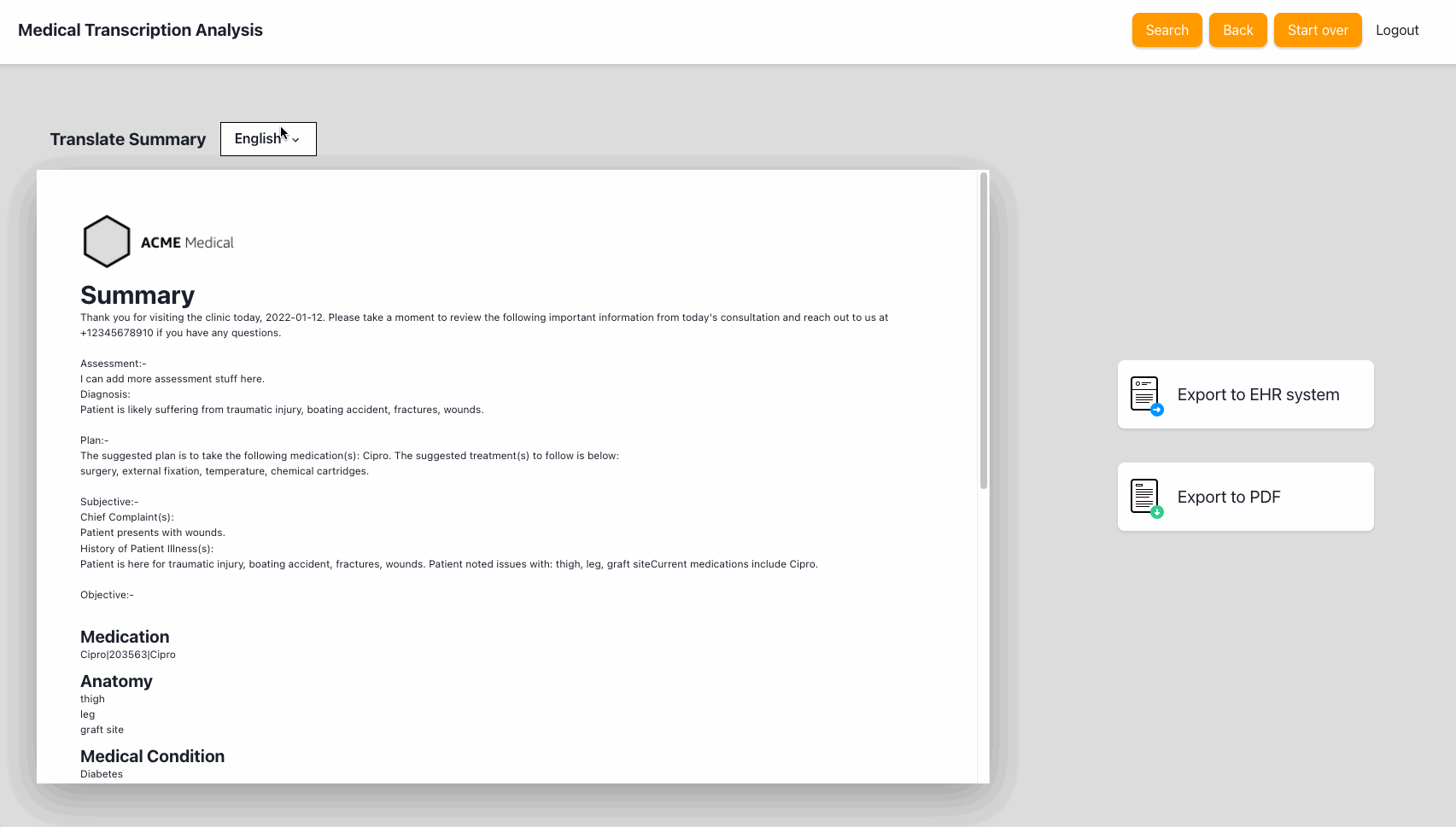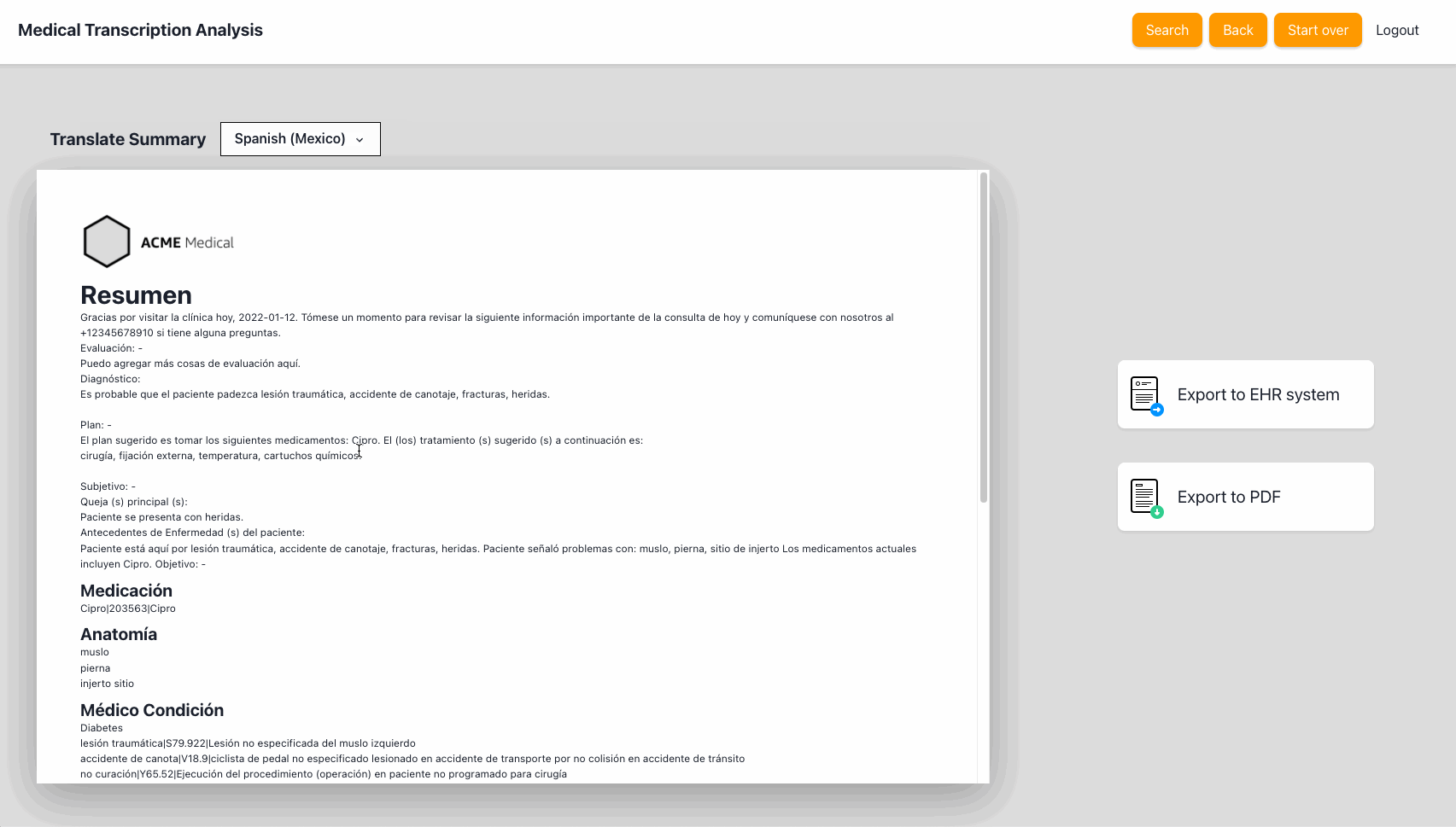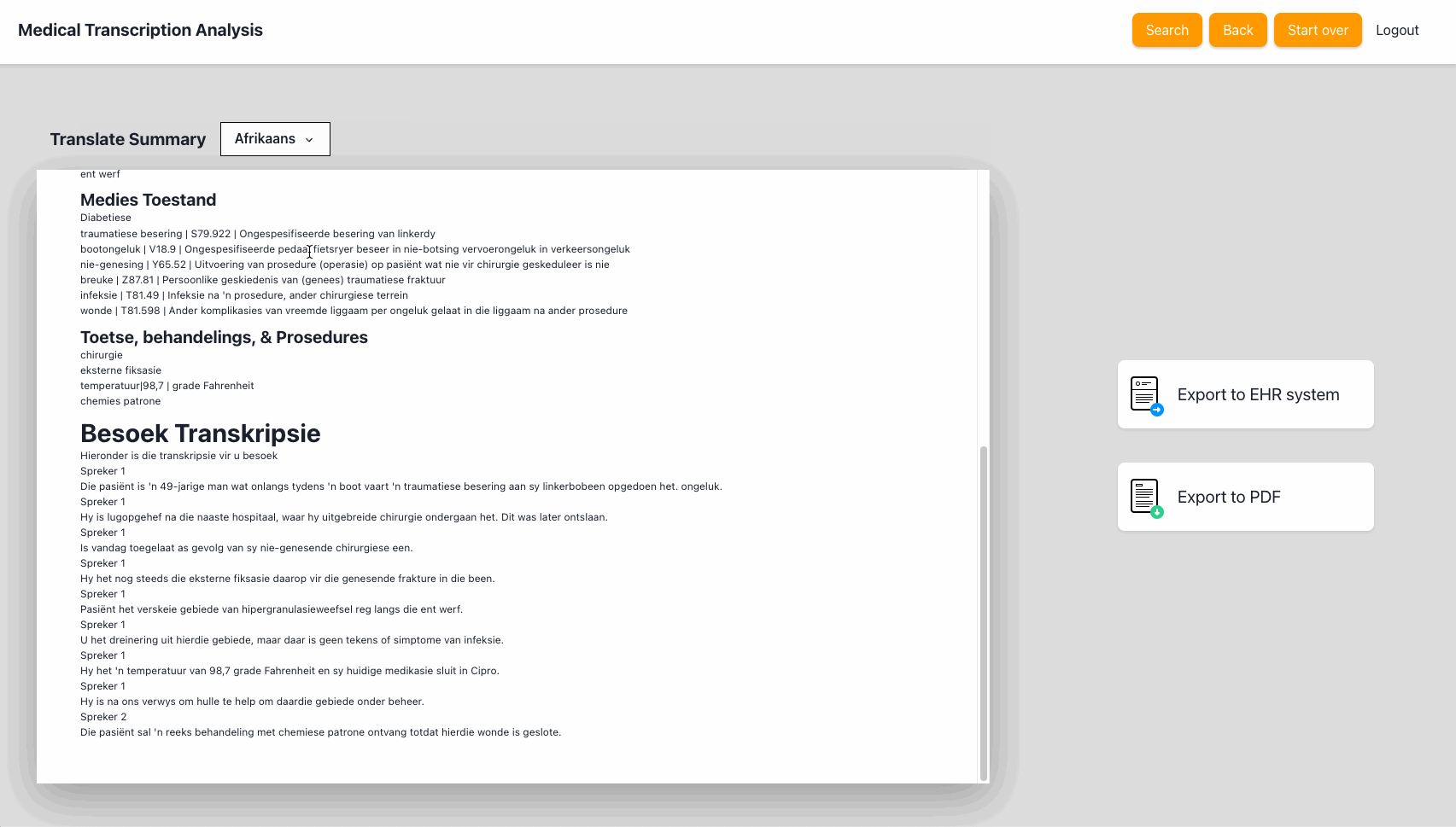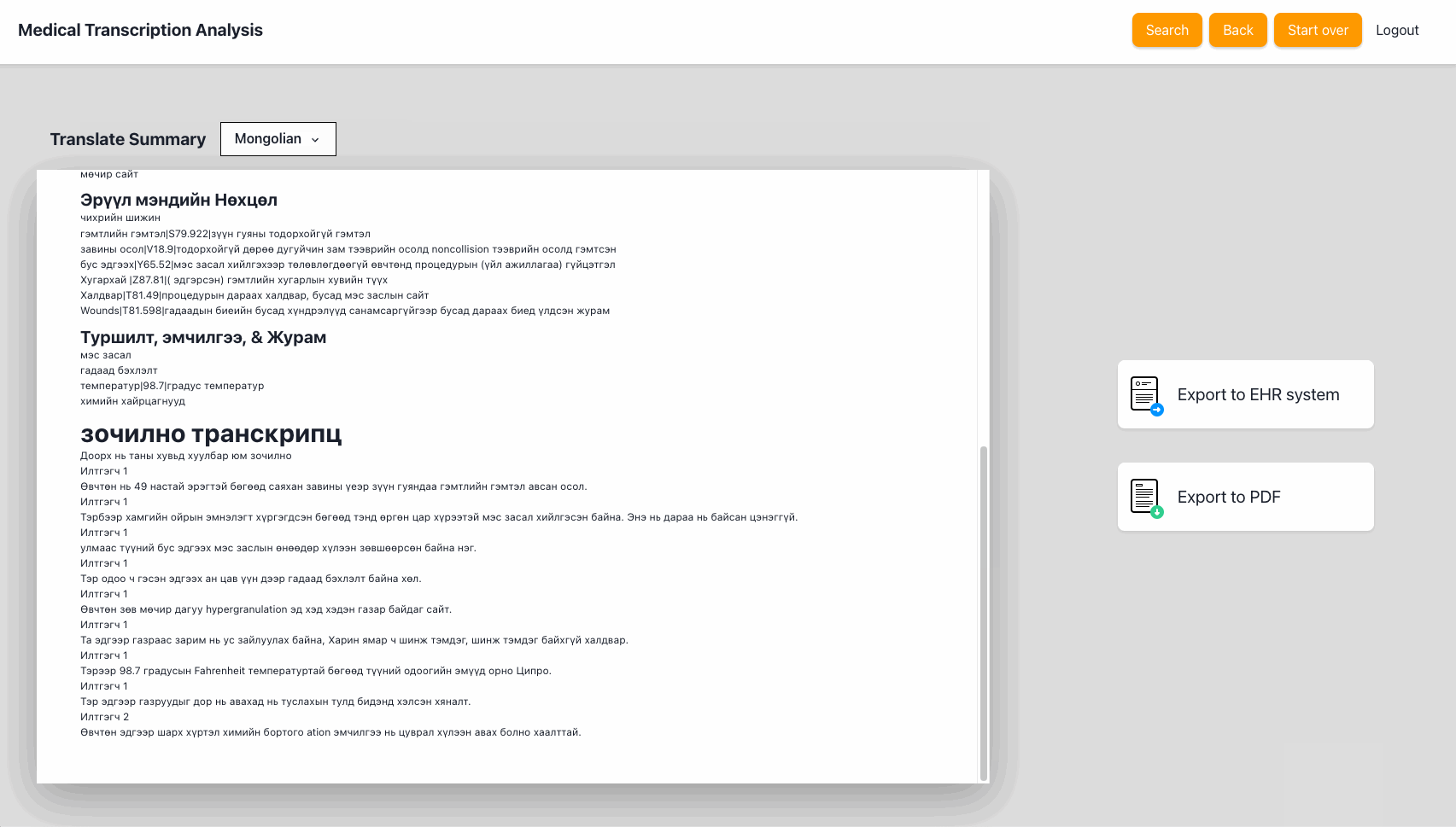
UX improvements still in the backlog
Throughout the development of this tool, I've conducted around 20 1:1 user feedback sessions to test the new integrations and to identify significant usability issues. Unfortunately, the engineering team did not have bandwidth to implement any UX improvements outside of the initial scope.
Below are some final designs I created to address the most critical usability issues found, but that ultimately were not implemented.
Homepage
Include high-level information about the application in the homepage to provide context. Clearly indicate the different ways available to get started.
MTA homepage (original version)
MTA homepage with recommendations to improve the UX
Help users understand how the application works.
Provide quick and concise information to help users create a mental model of how the application works and the actions needed.
Improve the way detected entities are represented in the transcript and in the "Entities Extracted" area.
Below you'll se an exploration of three ways that the detected entities could be represented. It is also important to improve how the relationship between the detected entities are represented in the transcript and in the "Entities Extracted" area. More UX research and more design iterations are needed to identify the most optimal option. Unfortunately, our team had to move on to the next project and more research wasn't possible.
The mocks below also improve the overall navigation and visualizes the steps required in the process.
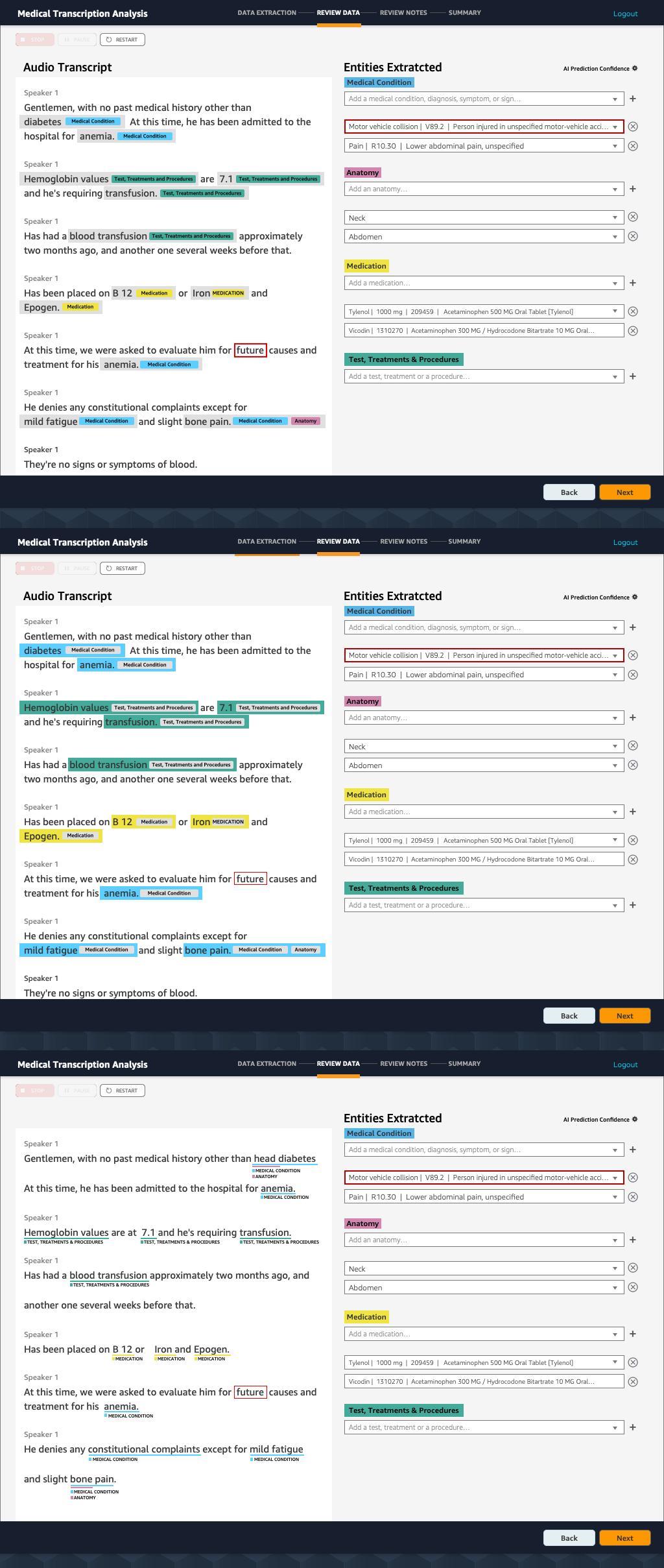
Enable users to change the confidence score threshold
Several users requested to be able to be able to change this setting. Some wanted to limit of options presented, while others wanted to see more options available, but that weren't presented due to this limit.